
 欧美性爱qvod
欧美性爱qvod
前两天,英伟达第三季度财报终于出了。服从是预期中的向好,营收351亿好意思元,同比增长93.7%。净利润193.1亿好意思元,同比增长109%。
简便蓄意等于上个季度英伟达共赚2542亿东说念主民币,净利润1398亿,平均每天爆赚15亿东说念主民币,尽头于一天赚出8套北京价值2亿的四合院。
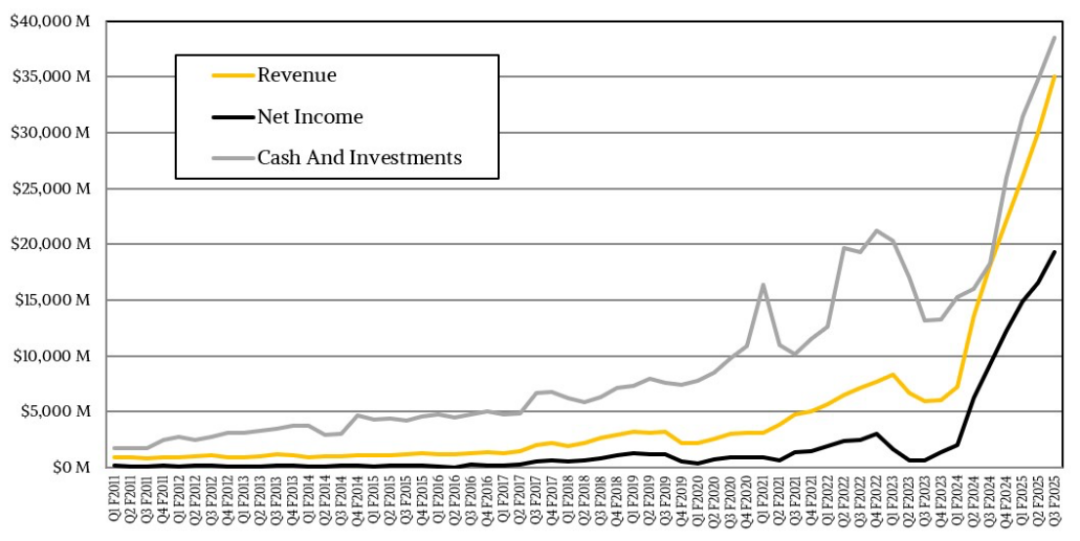
GPU的出现就符号着赢利,三季度英伟达的毛利率高达74.6%。什么倡导?被誉为“大当然的印钞机”、将钟睒睒捧上中国首富宝座的农夫山泉,毛利率也不外60%
英伟达的图形处理单位(GPU)工夫之不凡,已广为东说念主知。相较之下,国产 GPU 的影响力则显得较为有限。
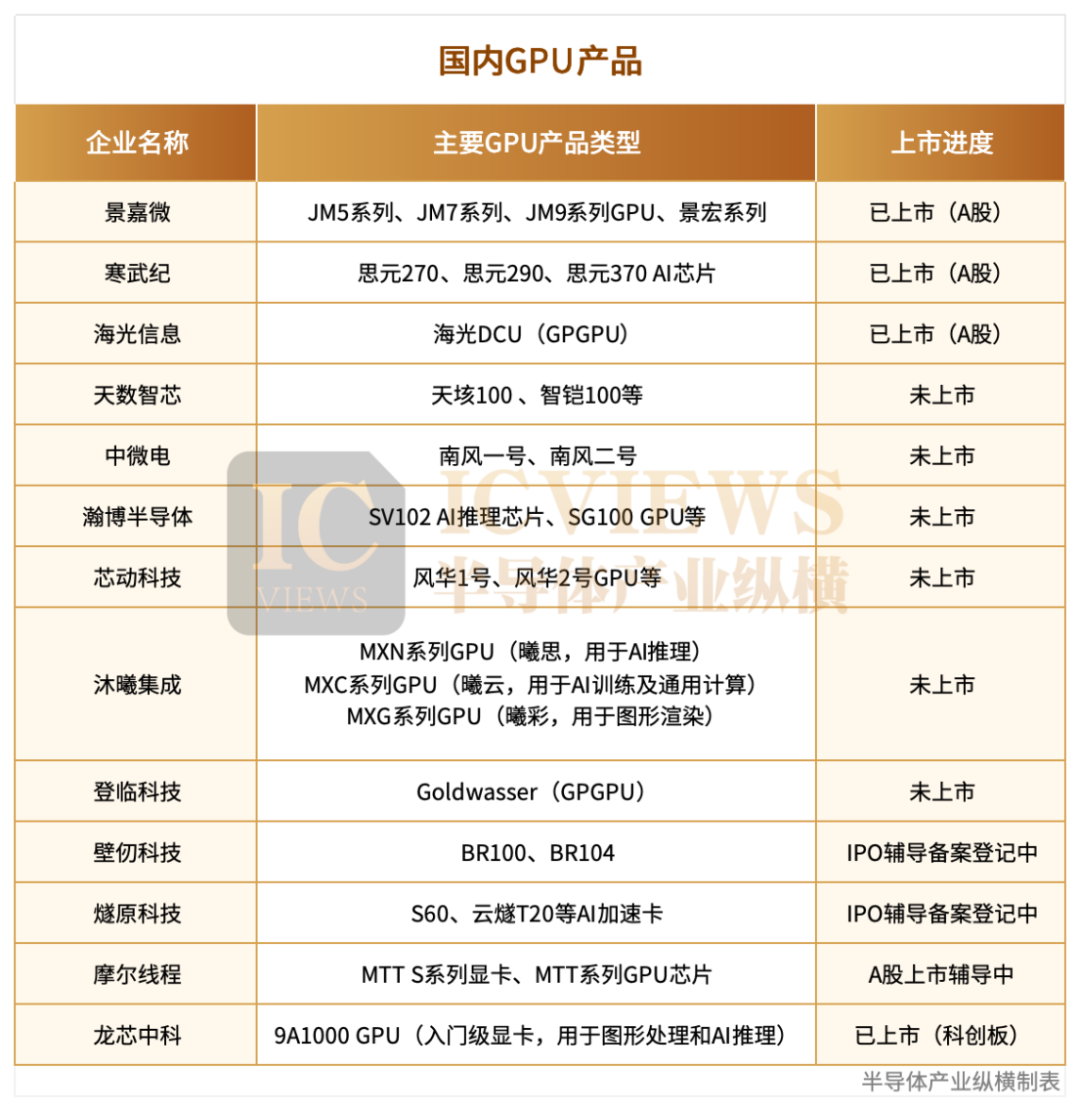
联系词,连年来,中国国内的好多GPU企业初始崭露头角。通过握续的参预和发愤,国产GPU在性能、功能和应用范围等方面齐有了升迁,徐徐赢得了市集的招供和用户的信任。国产GPU不仅在传统图形处理范围取得了弘扬,也大概在东说念主工智能、高性能蓄意等新兴范围展现出一定的竞争力。
01
景嘉微
景嘉微是国内自主学问产权图形GPU领军企业,是国内少数几家坐蓐GPU且具有自主学问产权的公司。
景嘉微的GPU 家具包括 JM5400、JM7200、JM9 系列和景宏系列,秘密传统范围和新兴范围。
JM5400是景嘉微早期推出的一款GPU家具,符号着国产GPU的起步;JM7200/7201系列适用于桌面办公、图形职责站及有高条目的图形生成及败露等范围。景嘉微在JM7系列期间已完成了与主流国产CPU与操作系统的适配职责。
JM9系列是景嘉微的第三代GPU家具,包括JM9100和JM92系列,它们在前两代的基础上进一步优化了性能与功耗,最低功耗不到2W,全面搭救国产CPU、国产操作系统和国产固件,可正常应用于PC、条记本电脑、工控机、图形职责站等蓄意机开拓。
景宏系列是景嘉微本年得胜研发的家具,主要用于AI 考研、AI 推理和科学蓄意等范围。凭证公告,景宏系列搭救INT8、FP16、FP32、FP64等羼杂精度运算,搭救全新的多卡互联工夫进行算力彭胀,适配国表里主流CPU、操作系统及就业器厂商,大概搭救刻下主流的蓄意生态、深度学习框架和算法模子库,大幅裁减用户适配考据周期。
02
天数智芯

天数智芯通用GPU家具天垓、智铠系列
天数智芯通用GPU家具适配主流CPU芯片/就业器厂商,大概搭救国表里主流AI生态和多样深度学习框架。天数智芯也曾发布了两款自主研发的通用GPU家具天垓100、智铠100,具备应用秘密广、开发易迁徙、性能可预期、全栈可定制、使用成本低等脾气。
天垓100是天数智芯推出的全自研通用GPU考研家具。它选拔通用GPU架构,兼容国际主流GPU通用蓄意模子,搭救国表里主流AI生态和深度学习框架及原生算子。2022年底,天数智芯曾文告天垓100累计销售订单已冲破5亿元。
智铠100系列加快卡基于通用GPU架构,搭救多种视频规格解码、800+通用请示集、国表里主流深度学习开发框架。兼容CUDA生态,搭救市集主流生态,高达128路视频接入。平均迁片时期相较市集主流家具下跌50%以上,生态应用迁徙连忙。
天数智芯推出的国内首个通用蓄意应用开发及评测平台DeepSpark握续迭代,收尾现在已积聚300+考研和80+推理模子示例,搭救主流AI应用框架,提供多维度测评体系。
天数智芯自主算力集群有谋划大概灵验搭救OPT、LLaMa、GPT-2、CPM、GLM等主流AIGC大模子的Pretrain和Finetune。同期适配搭救了清华、智源、复旦等在内的国内多个研讨机构的开源大模子欧美性爱qvod。
03
中微电
中微电的GPU家具有:南风一号、南风二号、南风三号。“南风一号”GPU主要应用于信创蓄意机败露可清闲党政、金融及安防等信创产业链专用整机电脑PC显卡需求。“南风二号”提供高性能并行蓄意才智,清闲就业器、考研机、推理机、边际蓄意、科学仿真蓄意、智算中心等东说念主工智能市集需求。
昨年12月,中微电科技“南风一号”显卡(NF1001)导入了世恒TD120A2整机。符号着家具也曾通过了中国长城各项功能、性能、可靠性、兼容性、相识性等测试。“南风一号”也与麒麟操作系统(V10 SP1)、激越处理器(D2000、FT2000)、奇安信浏览器等多家国产开拓、应用完毕兼容性互认证。“南风一号”从“家具”认真转型为“商品”。
本年4月,中微电文告“南风二号”中枢IP研发完成,通过了FPGA的仿真测试。实践服从标明,“南风二号”AI推感性能达到48TOPS,基本完毕了国度工业和信息化部揭榜挂帅名堂和深圳市科技要紧专项名堂的参数宗旨。
04
芯动科技
芯动科技也推出了GPU家具:风华1号、风华二号。
风华一号发布于2021年,是首款国产高性能4K级显卡GPU。包括“风华1号”A型卡(单芯桌面端)、“风华1号”B型卡(双芯就业器端)两款,选拔12nm制程工艺。搭救国产新基建5G数据中心、桌面、元天地、云游戏、云桌面等千亿级产业。
风华二号发布于2022年8月,是一款集超低功耗、强渲染、4K高清三屏败露、4K视频解码、智能AI蓄意于一体的桌面和条记本GPU,选拔自研LPDDR5X显存,带宽达到10Gbps,整卡实测功耗4~15W。
工控范围,芯动科技的风华 2 号 GPU 已在各大城市轨说念交通系统的自动售检票系统中完毕大范围商用。该系统中的自动检票机、自动售票机和半自动售票机等开拓,选拔风华 2 号 GPU 后,可搭救 4 屏败露和万古期低功耗高相识运行,
耗尽电子范围,天天电竞发布的国潮电竞专科显卡品牌 “赤兔”,搭载了芯动科技自研的风华 GPU 芯片。
05
沐曦集成
本年9月,沐曦集成近期完成了新一轮股权融资,参与这次投资的机构包括浦东创投集团、上海科创基金、湘江国投、启夏老本、中卫颐和及上海源庐加佳信息科技有限公司等多家闻明投资方。
现在沐曦集成电路的GPU家具包括:曦念念N系列、曦云C系列、曦彩G系列。
曦彩G系列GPU是针对图形渲染加快的惩办有谋划,沐曦自主学问产权架构提供不凡的图形图像渲染与视频处理才智, 可正常应用于元天地、云桌面、云游戏、云手机、数字孪生、XR等场景。
曦念念N系列首款家具曦念念 N100是一款面向云表数据中心应用的东说念主工智能推理GPU,自2022年底家具量产以来,已在颖慧交通、颖慧安防、智能转码等东说念主工智能范围赢得正常应用。沐曦集成与眸瑞科技纠合发布的“贴图超分”工夫,依托曦念念N系列AI推理GPU的重大算力,初度将AI超分得胜应用到了3D模子范围。
曦云C系列通用GPU(GPGPU)芯片是针对智算及通用蓄意的齐全惩办有谋划,沐曦自主学问产权架构提供重大高精度及多精度混划算力,可正常应用于智算以及通用蓄意、素质和科研等场景。曦云C500单卡算力高达30TFlops FP32,单卡64GB HBM2E高带宽显存,带宽1.8TB/s,这张卡还配备自研MetaXlink高速接口,符合于大模子考研。4卡既不错搭救65B大模子推理,8卡不错搭救130B模子推理。
2023 年,沐曦联袂智谱华章、优刻得共同发布了国产首台 GPU 千亿参数大模子训推一体机。首批客户是北京航天总病院、数字宁夏开拓运营有限公司。
06
登临科技
动漫av登临科技成立于2017年,现在Goldwasser系列家具也曾完毕范围量产,团队死力于于以GUGPU为中枢构建高性能蓄意平台。
Goldwasser 系列家具:包括边际蓄意家具 Goldwasser UL,功率 25-35W,INT8 算力 32-64TOPS;半高半长的就业器蓄意卡 Goldwasser L,功耗 40-70W,提供 128-256TOPS 算力;另有一种全高全长的 Goldwasser XL,输出 512TOPS 算力。
该公司最引东说念主矜重的所在是,宣称其自主革命的通用GPU 具有“与 CUDA/OpenCL 等编程模子兼容的蓄意架构”,使其大概很好地与 Nvidia 竞争,但同期也可能欺诈 Nvidia 最大的竞争上风——CUDA 与之抗击。
据称,在首代Goldwasser家具量产后一年内,登临科技完成国内主流运营商、操作系统、CPU、互联网企业、东说念主工智能框架、就业器企业的兼容互认证,并发布登临瀚海生态经营。
登临科技创举东说念主李建文、登临科技纠合创举东说念主王平本硕均就读于清华大学,民众运营副总裁杨剑曾任华为民众供应链副总裁,其研发团队领有永远的GPU研发和买卖家具化警戒。此外,登临科技在硅谷、成齐、杭州等城市共建树了七个研发中心。
07
壁仞科技
壁仞科技创立于2019年,死力于于研发原创性的通用蓄意体系,建立高效的软硬件平台,同期在智能蓄意范围提供一体化的惩办有谋划。现在,壁仞科技首款国产高端通用GPU壁砺系列已量产落地。
BR100系列通用GPU芯片是国内算力最大的通用GPU芯片,包括BR104和BR100两各人具。基于自主原创的芯片架构开发,选拔7纳米工艺制程,并联结了包括Chiplet(芯粒工夫)等在内的多项业内前沿芯片设想、制造与封装工夫。其中BR104对标英伟达2020年推出的A100、BR100对标英伟达4nm芯片H100。
此外,壁仞科技还推出了“壁砺”系列算力家具,这些家具进一步丰富了壁仞科技的GPU家具线,清闲了不同客户和应用场景的需求。
壁仞科技与波浪科技互助推出了搭载 BR100 的 OAM 就业器 “海玄”,其峰值浮点算力达 8PFLOPS,最大功耗为 7KW,为数据中心提供了高能效、低 TCO(总领有成本)的数据中心集群有谋划,可清闲数据中心对大范围数据处理和高性能蓄意的需求,搭救云蓄意、大数据分析、东说念主工智能等多种应用的运行。
08
摩尔线程
最近,证监会官网败露,摩尔线程智能科技(北京)股份有限公司(下称摩尔线程)在北京证监局办理请示备案登记,认真启动A股上市进度,请示机构为中信证券股份有限公司。
摩尔线程亦然国内仅有的在B端和C端均有布局的国产GPU企业,其芯片选拔先进MUSA架构。
现在家具有MTT S系列显卡、MTT系列GPU芯片、智算集群惩办有谋划。MTT S系列显卡包括MTT S80、MTT S70、MTT S50、MTT S3000、MTT S4000。
MTT S80被称为“国产游戏第一卡”,是国内唯独不错搭救DX12的耗尽级显卡。发布于今,该卡的Windows驱动也曾迭代多个版块,已完毕国内TOP50热点游戏100%兼容,已跟踪突出400款游戏的运行情况,累计认真适配和优化游戏185款。收尾2024年10月,MTT S80在图形测试软件3DMark 11中的得益,已升迁至4.5倍。
MTT系列GPU芯片包括:苏堤、春晓、曲院。苏堤是中国首颗全功能GPU芯片,曲院则是基于摩尔线程自研架构的最新一代全功能GPU芯片,大概提供东说念主工智能所需的综划算力,尤其是针对大言语模子考研和推理的处理才智。
此外,针对大模子考研,摩尔线程也曾落地了宇宙产的夸娥(KUAE)智算中心全栈惩办有谋划,从千卡智算集群到万卡集群有谋划。
09
结语
从现在的情况来看,部分国产 GPU 家具在性能上也曾取得了一定高出,如壁仞科技的 BR100 系列 GPU,其峰值算力突出了英伟达现在在售的旗舰蓄意家具 A100 GPU 的三倍,并创造了民众通用 GPU 的算力纪录,大概清闲一些对算力条目较高的应用场景需求。
同期,一些国产 GPU 芯片选拔了先进的制程工艺和封装工夫,在升迁性能的同期,灵验抑制了功耗。举例芯动科技的风华 2 号,在低功耗格式下职责功耗仅在 4w 傍边,能效比远优于市集同等算力家具。
越来越多的国产 GPU 厂商意志到生态开拓的紧要性,并积极与高卑鄙企业、科研机构等伸开互助,共同构建完整的产业生态。如摩尔线程与广阔行业互助伙伴纠合展示了基于其智算集群的丰富行业大模子应用有谋划,股东了国产 GPU 在各范围的应用和发展。
与英伟达、AMD 等国际巨头比拟欧美性爱qvod,国产 GPU 在全体工夫水平上仍存在一定差距,格外是在高端 GPU 市集,海外家具在性能、能效比、功能完整性等方面仍占据上风。但千锤百真金不怕火,方成正果。国产GPU的发展进度,亦然其束缚追求工夫高出的经由。